




Thesis by Claire Bizon Monroc: « Apprentissage par renforcement multi-agent pour le contrôle dynamique de parcs éoliens» (Multi-agent reinforcement learning for the dynamic control of wind farms).
When wind turbines are assembled on a wind farm, under certain wind conditions they may interact with each other through what is known as the wake effect. When a wind turbine captures the kinetic energy contained in the wind, due to the conservation of energy, the wind flow downstream experiences a decrease in speed and an increase in turbulence. As a result, wind turbines located in this wake see their electricity production fall significantly, while also undergoing increased mechanical fatigue. These wake effects (Figure 1) cause annual production losses of as much as 20%.
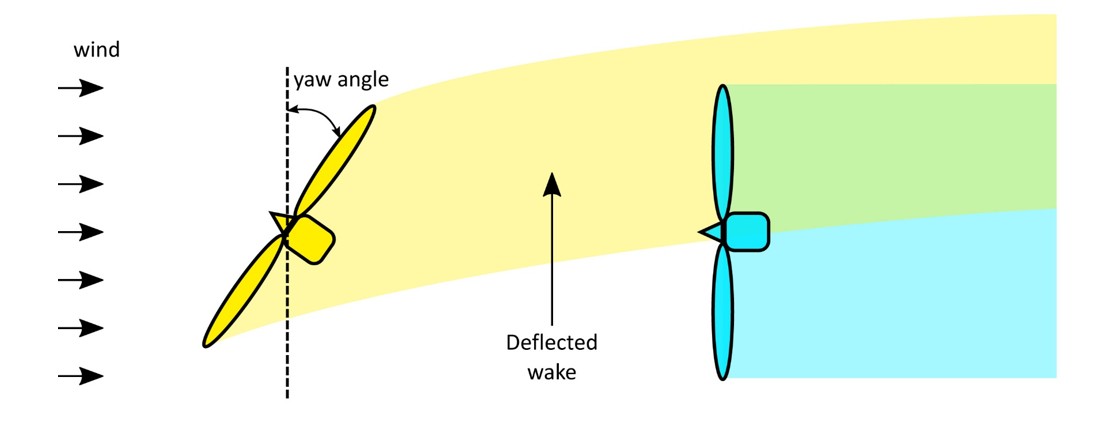
It is possible to influence the wakes by controlling specific turbine actuators. Among these, the yaw angle, defined as the angle between the wind direction and the rotor plane, allows the wake to be deflected and thus potentially provides more energy to the wind turbine affected by it (Figure 2). However, to maximize their individual power, wind turbines are positioned perpendicular to the direction of the prevailing wind (i.e., the yaw angle is zero), and decreasing or increasing the value of this angle results in a loss of power for the turbine concerned. The aim is therefore to shift from an individual control strategy to a collective strategy designed to maximize the power supplied on a wind farm scale.

Finding the combination of yaw angles maximizing production across the entire farm is a challenging optimization problem. Conventional control strategies require modeling of complex aerodynamic interactions between turbines. However, the models are either too rudimentary to produce optimal solutions in the field or too complex to allow for simulations on a farm scale, as the number of turbines increases. An alternative approach consists in using measurements collected in real time on the wind farm: the idea is to design methods capable of learning the optimal combination of yaw angles by observing only the total electricity production.
However, there are a number of challenges associated with this optimization strategy:
- firstly, wake propagation times, which create a delay between a change in yaw and the point at which its impact on the farm’s production can be observed;
- secondly, the difficulty in measuring the exact contribution of each turbine's yaw change to total production;
- thirdly, these two problems — propagation time and reward attribution — become more complex as the number of wind turbines increases and the size of the research space expands.
In this thesis, wind farm control was framed as a multi-agent reinforcement learning (MARL) problem. Unlike traditional model-based control methods, reinforcement learning (RL) is a method that does not require prior knowledge of physical models. An RL agent learns to make better decisions through trial and error by interacting with its environment. The decentralized MARL approach proposed in this thesis consists in coordinating several RL agents — each agent controlling one turbine — to maximize the farms’ total production.
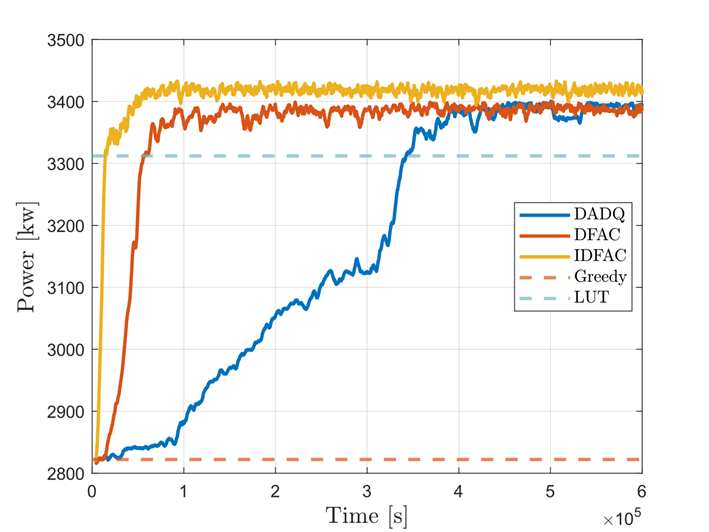
We proposed several decentralized MARL algorithms [1,2,3]. These algorithms are capable of taking into account the dynamic propagation of wakes in wind farms, and they are easy to apply to a large number of turbines due to their decentralized multi-agent nature. These algorithms were evaluated in reference simulators in the wind energy sector, for farms with between 3 and 36 wind turbines. In all cases tested, they enable a significant increase in production of up to 20% and more compared to the conventional strategy (known as “Greedy”) where all wind turbines are oriented to face the wind (Figure 3).
To facilitate future research into the application of reinforcement learning methods for wind farm control, we have also developed an open-source software library called WFCRL1 [4]. This enables easy interfacing of control tools widely used by the reinforcement learning community with the FLORIS and FAST.Farm wind farm reference simulators2.
Finally, from a theoretical point of view, we demonstrated the convergence of a multiscale algorithm within the MARL framework, where agent dynamics can be represented by a DAG (directed acyclic graph) [5]. This result provides a theoretical understanding of the experimental results in the thesis.
These results suggest that our RL algorithms could learn online from active wind farms. We are currently continuing our research to further improve convergence time and robustness in windy conditions. We are also working to extend our algorithms to take into account fatigue loads (induced by wakes and turbulence), as well as to enable wind farms to provide services to the electricity grid, for example by following a power signal requested by a grid operator.
1 https://github.com/ifpen/wfcrl-env et https://github.com/ifpen/wfcrl-benchmark
2 Both developed by the American National Renewable Energies Laboratory (NREL)
References:
- Bizon Monroc, C., Bouba, E., Bušić, A., Dubuc, D., and Zhu, J. (2022). Delay-aware decentralized q-learning for wind farm control. In 2022 IEEE 61st Conference on Decision and Control (CDC). IEEE.
>> DOI : http://dx.doi.org/10.1109/CDC51059.2022.9992646
- Bizon Monroc, C., Bušić, A., Dubuc, D., and Zhu, J. (2023). Actor critic agents for wind farm control. In 2023 American Control Conference (ACC). IEEE.
>> DOI : http://dx.doi.org/10.23919/ACC55779.2023.10156453
- Bizon Monroc, C., Bušić, A., Dubuc, D., and Zhu, J. (2024). Towards fine tuning wake steering policies in the field: an imitation-based approach. TORQUE 2024. IOP Publishing.
>> DOI : http://dx.doi.org/10.1088/1742-6596/2767/3/032017
- Bizon Monroc, C., Bušić, A., Dubuc, D., and Zhu, J. (2024). WFCRL: A Multi-Agent Reinforcement Learning Benchmark for Wind Farm Control, NeurIPS 2024 Datasets and Benchmarks Track.
>> DOI : http://dx.doi.org/10.48550/arXiv.2501.13592
- (under review at SIMODS, preliminary version presented at ARLET Workshop, ICML 2024) Bizon Monroc, C., Bušić, A., Dubuc, D., and Zhu, J. (2024). Multi-agent reinforcement learning for partially observable cooperative systems with acyclic dependence structure.
>> https://hal.science/hal-04560319/document
Scientific contacts: Jiamin Zhu, Donatien Dubuc