





High-Performance Computing (HPC) is a scientific field involving both mathematics applied and computer science, with applications in numerous fields, including climate, energy, sustainable mobility, etc. In all of these fields, we often need to simulate large-scale physical phenomena with mathematical models that require a lot of computing time and storage space.
The aim of HPC is therefore to optimize the use of resources - machines, software, algorithms, development methodologies, etc. - to process large and complex problems from a wide variety of applications, accurately and in reasonable time.
These simulations are performed using supercomputers1 that have CPUs2 with a large number of cores3 (for example 18 for Ener440 from IFPEN, or 64 for Irene from TGCC or 96 for Adastra from GENCI-CINES).
Despite their intrinsic power, the question now is how to calculate more efficiently with these machines, their multi-core processors, their complex memory hierarchy and the sophisticated computing units. In particular, this concerns fast and efficient core synchronization.
Shared-memory synchronization has been around for a long time and numerous models have been proposed, which can be found in different compilers used in HPC. For the traditional parallelization of a shared-memory code, core synchronization is aimed, firstly, at organizing calculations in the right order (via the insertion of barriers4) and, secondly, at guaranteeing the capacity to combine the results produced by all of the cores (in order to reduce them to a scalar result). In all cases, the time required should be kept to a minimum, but for processors with a large number of cores, the extra cost in computing time associated with the intensive use of these standard compiler synchronization mechanisms (such as GCC or Intel) is significantly high. They can even become performance bottlenecks for massively parallel codes.
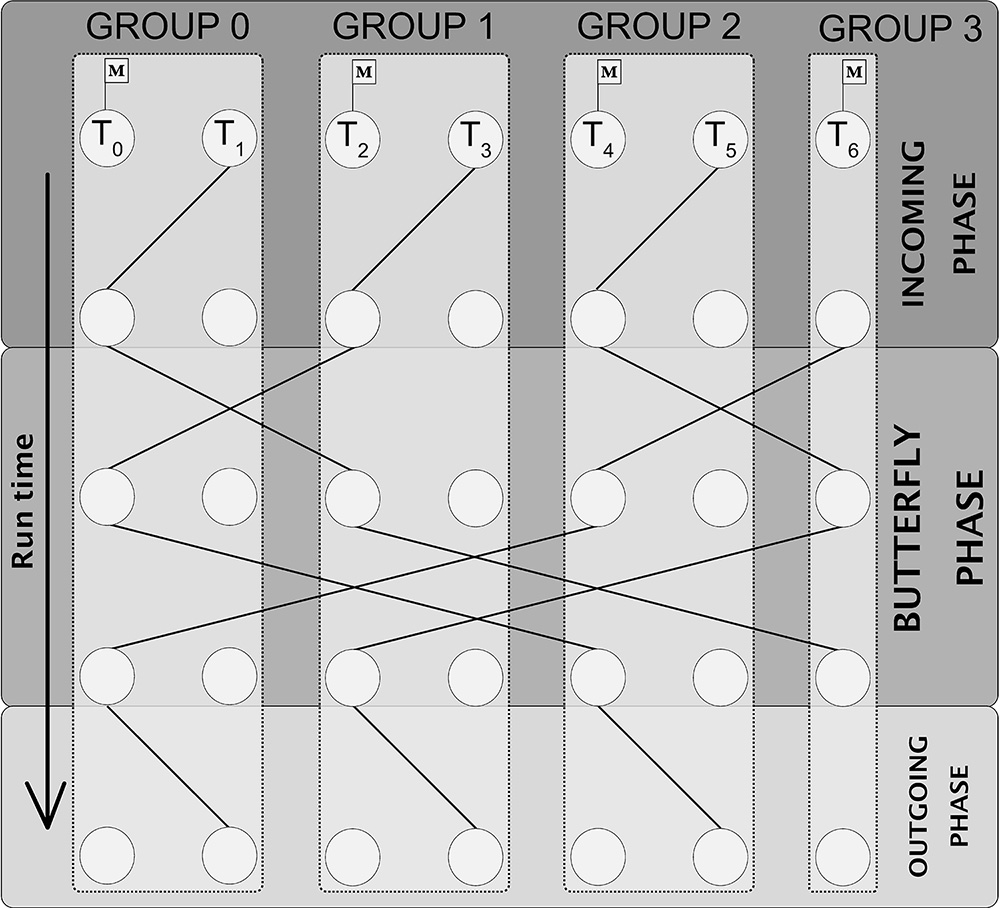
Figure 1 illustrates the Extended Butterfly synchronization barrier, proposed within the framework of a thesis5 conducted at IFPEN, for shared-memory parallel codes in order to address this problem. Its originality lies in the implementation of group synchronization6 on two levels: intra-group then inter-group synchronization [1]. The number of steps required for synchronization depends on the log of the number of groups, which means that for seven cores, four steps are sufficient to synchronize them.
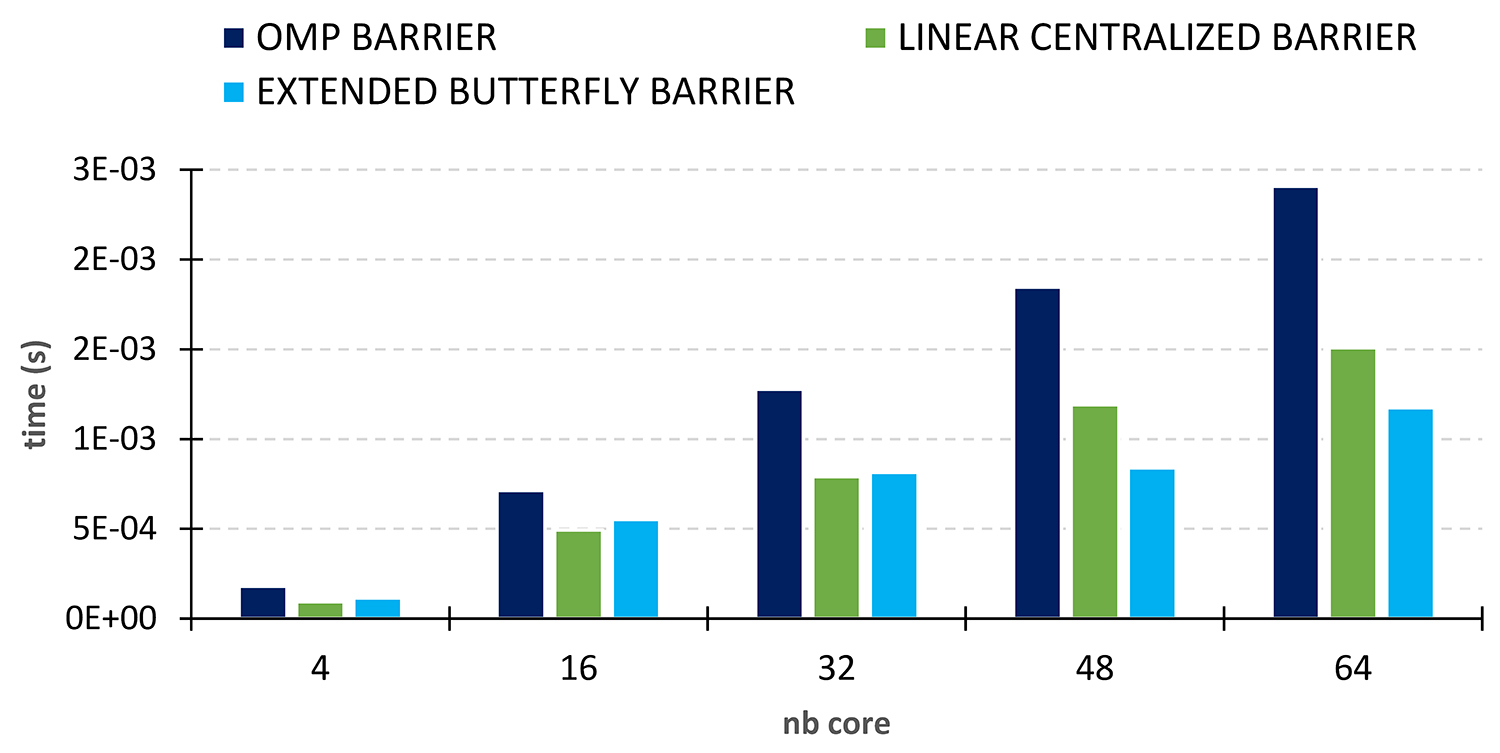
The results of the performance tests conducted (figure 2) show that this barrier (light blue histogram) requires a shorter synchronization time (or latency) than the OpenMP programming interface barrier with GCC compilers (dark blue histograms).
Our Extended Butterfly barrier was then used as a support for reduction operations. Our Extended Butterfly Reduction method is up to four times faster (for 64 cores) than the OpenMP reduction with GCC on the AMD Milan processor (figure 3).
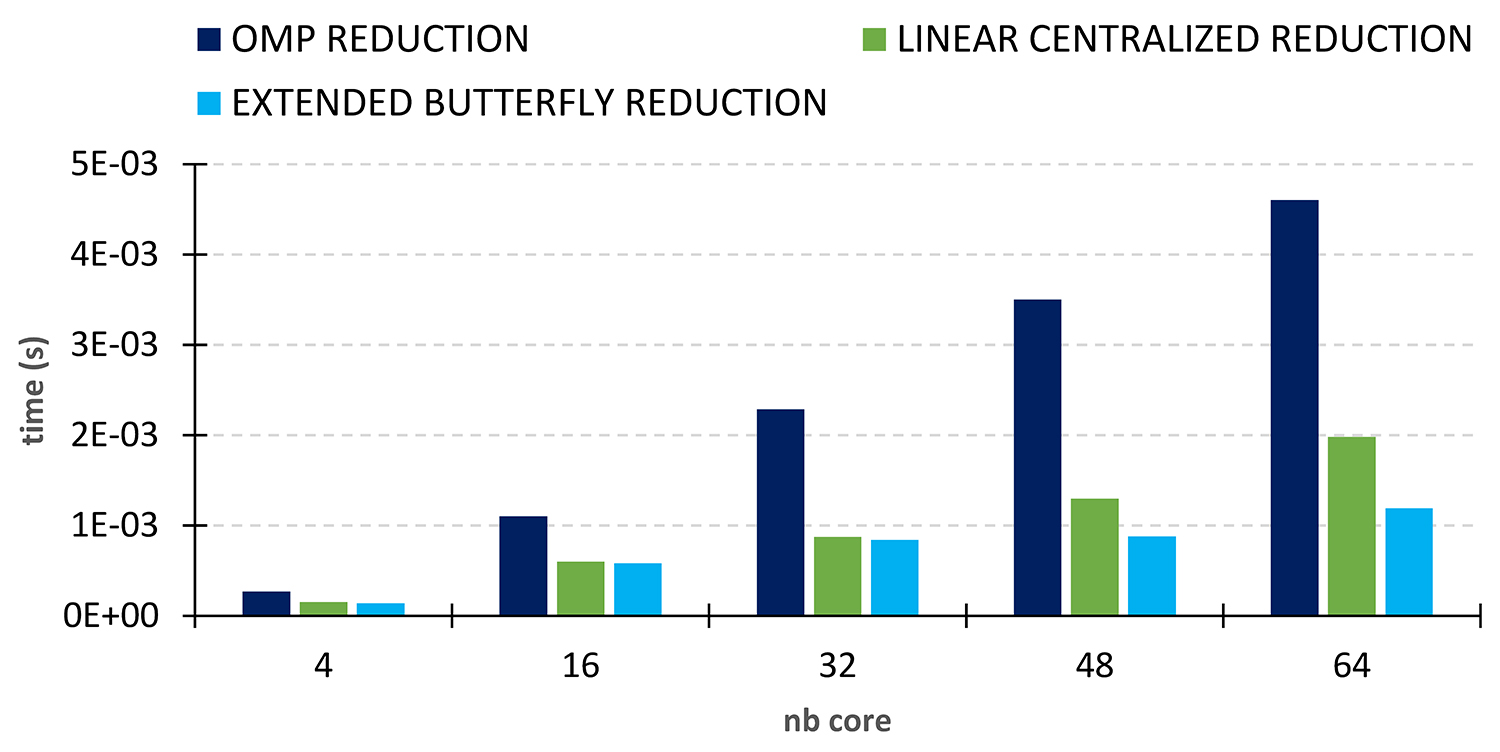
The barrier and Linear Centralized reduction (green histograms) represent old methods implemented in MCGSolver7, IFPEN’s massively parallel library of linear solvers. Once again, the new methods Extended Butterfly lead to significantly better performances when the number of cores exceeds 40.
In summary, the computing power provided by new processors, thanks in particular to the large number of cores embedded, raises the issue of their optimal exploitation. Our new Extended Butterfly method proposes an effective approach to address this problem, with several benefits in terms of core synchronization. These methods have been integrated in the MCGSolver library.
1- Like Adastra (GENCI-CINES), the most recent machine that is in the top 3 of the 2022 Green500 rankings of supercomputers.
2- Central Processing Unit.
3- A core is a set of circuits capable of independently running programs.
4- Action designed to suspend the calculation of some cores while waiting for the others.
5- A. Mohamed El Maarouf, Factorisation incomplète et résolution de systèmes triangulaires pour des machines exploitant un parallélisme à grain fin (Incomplete factorization and resolution of triangular systems for machines exploiting fine-grained parallelism). Bordeaux University, 2023. HAL : tel-04429547 >> https://theses.hal.science/tel-04429547
6- Algorithmic notion introduced as part of this research.
7- Multi-Core multi-Gpu Solver.
Reference:
-
A. Mohamed El Maarouf, L. Giraud, A. Guermouche, T. Guignon, Combining reduction with synchronization barrier on multi-core processors, CCPE Journal, 2023.
>> DOI : 10.1002/cpe.7402
Scientific contacts: aboul-karim.mohamed-el-maarouf@ifpen.fr and thomas.guignon@ifpen.fr